We need to talk about parentheses
Programming languages come in all shapes and sizes. There are pretty simple languages and really complex ones. But what unites most of these languages is the syntax. There are many languages so-called C-like, as they share many syntax ideas with C language, which includes consistent indentation, grouping, scoping, and infix notation. And many other syntax aspects usually are common in a majority of languages.
But there’s one language, that is different from the others. It has a long story and research behind it. This language, developed in the late 1950s, and evolved since, still being alive up to our days. I’m talking about Lisp, of course.
And one of the most well-known things about Lisp is:
That’s gonna be today’s topic - why parentheses, how to deal with those, what features we can gain from those, and what tools we’ve come up with over the years of Lisp hacking.
The thing is, Lisp is notoriously known for its parentheses, as for many this is its main feature they will defend at all costs. However, for some reason, novice computer scientists fear these parentheses. This produces a lot of various memes, like this one1:
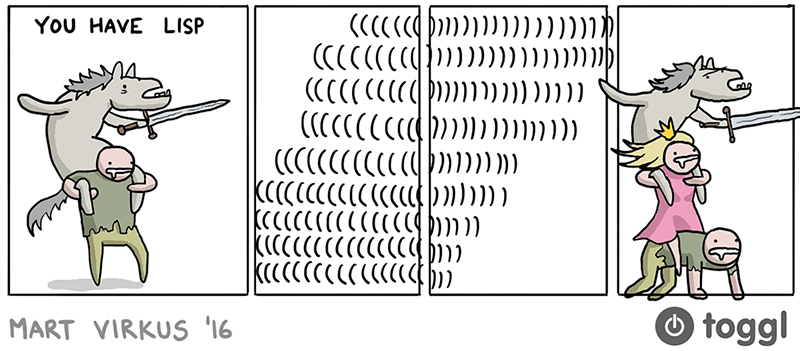
I guess this pretty much illustrates how most programmers, who are unfamiliar with Lisp, see the idea of parentheses. I often hear pretty common rants, that usually come down to one thing - there are too many parentheses even for the simplest things! And I agree, sometimes Lisp can be overwhelmed with parentheses for seemingly no reason.
To explain why parentheses are important let’s look at this small part of Rust code from some imaginary program:
let foo = 10;
let bar = foo + 32;
foo * bar
In this code we declare two immutable variables: foo, and bar, and assign values 10, and 42 to them respectively.
Then we compute their product and return it?..
Now let’s look at the same code but in Scheme, which is a dialect of Lisp:
(let* ((foo 10)
(bar (+ foo 32)))
(* foo bar))
This code does exactly the same thing as Rust code but has whopping twelve parentheses. And for most programmers, this may seem ridiculous. Why on earth someone would want to insert this amount of parentheses for a such simple task, as defining two variables and computing their product? Yes, Lisp is old, and this may seem like some legacy that was carried by language since the 60s. But there’s a good reason for parentheses to be part of the language, and once you understand their value, you’ll likely never be able to program without them. Likely. Because parentheses are that good. But why exactly?
Why parentheses?
In this section, I will try to convince you that parentheses are good. However, I must warn you that this is a conclusion most programmers begin to agree with only after writing in Lisp for some time. So while many things may seem silly, keep in mind that sometimes silly things only seem silly.
Scope
As we saw, both Scheme and Rust examples do the same things:
- declare the variable
foo, and assign a value of10to it, - declare the variable
bar, and assign a sum offooand32to it, - multiply
fooandbar, and return result to outer scope.
But here’s the catch - what scope?
In the Rust example, all we see are two definitions and expressions, and there’s the question: do we need foo and bar after we produce their product?
In Scheme example we can directly see where variables are available, since Scheme uses lexical scope, the end of life of foo and bar will be at the last parenthesis of the let* block:
(let* ((foo 10)
(bar (+ foo 32)))
(* foo bar))
In Rust, we can’t really see the whole picture here and now, because Rust does not require explicit scoping for a definition to be part of the expression.
Although syntax implies that there’s nothing after the product is computed, thus foo and bar will go out of scope right after their product is computed (there’s no semicolon).
We can assume that the surroundings are as follows:
let result = {
let foo = 10;
let bar = foo + 32;
foo * bar
};
Thus explicitly defining the scope for foo and bar as the part of result computation process, just as in Scheme.
Which will then be used, but we will not be able to access foo or bar later in the program.
However, I see the following code much more often instead:
let foo = 10;
let bar = foo + 32;
let result = foo * bar;
We let foo and bar live til the end of the outer scope, even though we might not use it at all.
And another question to ask is how long result has to live?
Does it need to live til the end of the function?
These are questions that can be asked for both examples.
Usually, we don’t think about this much and don’t wrap each and every variable into explicit scope in such languages.
And Rust itself does a good job of keeping everything clean and dropping objects when those go out of scope.
On the other hand, the Scheme example explicitly states that both foo and bar are local to the scope of the let* and no one will expect to use those variables outside.
And this pattern is applied to all other places in the program because we must define scope, as some Schemes forbid inline definitions with define.
This might seem like a small advantage, if any, for most developers, and a made-up example. And this is, in fact, a made-up example but the thing is, I was a C programmer for the past 5 years, and I was working with low-level code (bare metal actually). And I have never seen the use of explicit scoping of variables. Yes, there’s no standard way of doing what Rust does here unless we use compiler extension, but this is not an option sometimes, and the syntax is kinda cumbersome. I find this a major problem when dealing with C because I always see about 10 uninitialized variables at the start of each function, where half of those are used only once. Somewhere. And thank god, if there are no global variables. In Lisp, I can directly see where the scope for a variable begins and ends, and this pleases me enough to bear with parentheses.
But, well, even if we’re not talking about statement expressions, still in C or Rust we can define the scope with two curly braces, and in Scheme, we need twelve in total. Why?
Up to this point, you already may think that Rust or even C is actually better in this regard, but Lisp has a secret sauce hidden in these parentheses, which a lot of languages strive to achieve. And the reason for this is related to how Lisp was implemented in the first place.
LISP itself is an abbreviation, that stands for LISt Processor. And everything that is enclosed by parentheses is a list in Lisp. This enables one interesting property, which allows us to define an interpreter in a small set of recursive rules, which describe how to deal with lists.
I’m not going into details on how Lisp works, but roughly, all the code is transformed into real linked lists, like the one we have in other languages, except that such a linked list can hold anything in it.
So in the case of the expression above, the list holds an let* name, and then it holds a list of lists, which in turn hold identifiers that the interpreter will later use to bind values.
This may not sound clear enough, so here’s an explanation of each and every parenthesis in the Scheme example:
( ;; start of the top level list
let* ;; the let* special form
( ;; list of binding lists
( ;; first binding list
foo ;; which binds the name foo
10 ;; to value 10
) ;; end of first inner list
( ;; beginning of a second binding list
bar ;; that binds the name bar to
( ;; another list, which is an expression
+ ;; that computes the sum of
foo ;; a value of binding foo, and
32 ;; literal value 32
) ;; end of the expression
) ;; end of the second binding list
) ;; end of the list of bindings
( ;; body expression that uses those definitions, which is also a list
* ;; that holds multiply function
foo ;; the name that is bound to 10
bar ;; and the name that is bound to 42 - a sum of `foo' and 32
) ;; end of body expression
) ;; end of the top-level list
So each parenthesis has its purpose in this small code block, but still, there are too many of those. And this is the problem because when reading the code, it is easy to make a mistake. Can you immediately see where’s the error in this snippet?
(let* ((foo 10)
(bar (+ foo 32))
(* foo bar))
I know where it is, but even with this knowledge, it is kinda hard to spot it while going through the code. This particular example will not work at all – compiler/interpreter will probably indicate the error. Experienced Lisp programmers also will notice this mistake, but this example indicates one glaring problem:
humans can’t immediately parse structure with a glance, and sometimes we have to count parentheses by hand.
And sometimes it is possible for parenthesis to be in the wrong place, and the code will still work, but the results will be not the expected ones.
It is fair to say that scoping is not a unique feature of Lisp, and is easily available in other languages, with fewer parentheses. So why even bother with all these extra parentheses? Sure, in this particular example the benefit is that we have to explicitly scope our code, in order to make it work. And although the example above is not real code, explicit scoping saves me a lot of time every day, by making the code easier to reason about.
But, remember, I’ve said that there’s a secret sauce hidden here, which is much more important, and this is why parentheses, are in fact kept to this day. Its macro system is one of the most powerful Lisp features, if not the most.
Macros
Let’s quickly recap what we know about Lisp syntax and its relationship with macros.
I’ve mentioned that everything that is enclosed within parentheses is a list. And not just any list, but exactly singly linked list. Yes, this is a pretty common data structure that is widely available in many languages and has certain uses and benefits. Most languages are stored as text, and there is a special tool, bundled with the language, that analyzes this text, and produces an abstract syntax tree, or AST for short. But Lisp is a bit different since all Lisp code is actually stored inside linked lists. And linked lists are our AST. That’s why Lisp is a list processor - it operates lists as it’s main data structure for code. This is called homoiconicity. And I hope, we all know the common properties of a single linked list:
- Recursive nature, and persistence;
- ϴ(n) lookup time;
- ϴ(n+1) insertion, deletion, or splicing at arbitrary element;
- And ϴ(1) for insertion and removal at the front of the list.
Most notably, since we’re able to split and concatenate lists, and our code is stored within lists, we’re able to manipulate AST how we want because it’s just data. Lisp, being a list processor, comes with a lot of functions for manipulating this data structure, which allows programs to modify other parts of the program, or write new programs. This property is often called Metaprogramming, and in Lisp programs writing or manipulating code is a very common thing. And thanks to the ability of code to manipulate code, Lisp core is very small, and the rest of the language is defined in terms of macros.
For example, think of how one could add an and operator to their language if there is no and built in.
First, let’s remember what and does:
- If a predicate is
true, we check the next predicate; - If a predicate is
false, we stop the process and returnfalse; - If all predicates are
true, we return the last term.
We can implement these rules as a recursive macro:
(defmacro and [pred & preds]
(if (empty? preds)
`(do ~pred)
`(let [p# ~pred]
(if p# (and ~@preds) p#))))
Here’s what happens.
We declare and macro that takes pred as its first parameter, and rest predicates as preds.
We check if preds is empty, and if it is, this means that we need to check only one pred.
If there are preds, we check the pred, and if it is true, we call and again with the rest preds.
It pred is false, we return it.
This is a simple recursive process, that checks its arguments one by one until there is nothing left. And keep in mind that this can’t be really done with the function, as we evaluate one argument at a time, while the function will first compute all predicates, and then iterate results.
Another example is Clojure’s threading macro:
(-> 1
(+ 2)
(* 9)
(/ 5))
Its definition is more complex, compared to and macro, but the purpose of -> is to remove a lot of nesting from our expressions and present them as computation steps.
What it does, is it takes 1, adds 2, multiplies the result by 9, and then divides the end result by 5.
Macros are evaluated at compile-time, so after compilation, there will be this expression instead:
(/ (* (+ 1 2) 9) 5)
This is exactly the same thing, but you can see that it is kind of backward, e.g. division goes first.
But since this is a tree, we know that reduction is going from the leafs up to the root.
And while the -> variant has two more parentheses, there is actually only one depth level, whereas in expanded form the nest level is 3.
So macros can help us with that at the cost of some additional parentheses, there will be one more example later involving a custom macro.
Macros are a very complex topic, that I’m not going to cover in this post, so if you’re interested you can start at Racket’s guide section for macros. Macros in Racket are hygienic and have their advantages and limitations, but there are also plain AST macros, as in Clojure, or Common Lisp. It’s fair to say that it is possible to implement a macro system that does not require parentheses, as done in Elixir, or Rust. However, Rust, for example, has hygienic macros, which are less powerful than the unhygienic ones, and uses a kinda different syntax from the main language. Elixir has both hygienic and unhygienic macros, and macros overall look pretty similar because language is defined in terms of lists, like Lisp, although with a different syntax.
Operator precedence
Most languages with infix operators have these complex operator precedence tables that you have to keep in mind every time you do something that involves multiple operators. And we all know that parentheses enforce precedence. So, what are the precedence rules for operators in Lisp? The answer is… there’s none!
As we saw in the previous section, the silly math example with addition, multiplication, and division had parentheses around each operator:
(/ (* (+ 1 2) 9) 5)
You could write this in C like this:
float res = (1 + 2) * 9.0 / 5.0;
But what if we look at this example?
float res = 6 / 2 * (1 + 2);
What’s the answer?
9 or 1?
It depends… on operator precedence:

If someone will write this as a generic expression, like a / b * (c + d), what would the intention be?
In Lisp we would not have such a problem:
(/ 6 (* 2 (+ 1 2))) ;; 1
(* (/ 6 2) (+ 1 2)) ;; 9
When I was working on raycasting there was plenty of math with a lot of computations often going on in a single formula. And I’ve actually was so glad that the formula I’ve translated this from was written with all parentheses in place, so the precedence was pretty clear.
The other benefit of both parentheses and prefix notation is that we do not have to repeat the same operators more than once.
C:
int res = 1 + 2 + 3 + 4 + 5 + … + N;
Lisp:
(+ 1 2 3 4 5 … N)
This seems like another minor advantage but actually lies deep inside Lisp’s core.
In Lisp, if we take the first element of such a list it will be a function +, and if we take the rest of the list, we’ll have (1 2 3 4 5 … N) list.
And in lisp we apply a function to a list of arguments, literally, so we can instead write (apply + '(1 2 3 4 5 … N)), and this will be the same as writing (+ 1 2 3 … N) directly.
This is how most Lisp interpreters work under the hood, except apply is a core primitive, which is available for us as a function too.
Now, still, there are a lot of parentheses if the examples I’ve shown above, so let’s think about how we can improve the situation. One possible solution would be to change language in such a way that parentheses are not required, or required less often.
Fixing the problem inside the language
The problem of too many parentheses in Lisp is real, and for a long time, people tried to solve it in different dialects. So there are several ways to improve the situation, but if you ask me, the solution is to learn to stop worrying and love the parentheses.
Using different parentheses
One solution is to use different parenthesis types, which are actually mean same thing, e.g. ( = [ = {.
Some Scheme dialects, such as Racket, allow usage of other kinds of parentheses to make a structure more apparent as long as parentheses are matching depth level:
{let* [(foo 10)
(bar (+ foo 32))]
(* foo bar)}
While not as pretty as the single parenthesis type version, it is easier to see the structure because different expression boundaries are marked explicitly. Also, curly braces will probably offend some die-hard Lisp hackers.
Using fewer parentheses and changing parenthesis semantics
Some dialects of Lisp use fewer parentheses for such expressions. For example in Clojure, this code would look like this:
(let [foo 10
bar (+ foo 32)]
(* foo bar))
Clojure uses both the reduction of unnecessary parentheses and different parenthesis kinds, but it is not just a stylistic change as in Racket.
In Clojure square brackets represent different data types, a vector to be precise, so you can’t write let with ordinary parentheses around bindings.
While not as generic as in Scheme, this actually makes sense and provides nice semantics allowing humans to parse code easier.
And as we saw in Racket, it is common to wrap non-callable forms into square brackets, except in Clojure this is explicitly required for many forms.
Removing parentheses
There also were countless attempts of removing parentheses completely and using indentation with minimal syntax to represent structure. The most recent attempt is Project Rhombus, formerly known as Racket 2. Here’s how the code above could look, accordingly to this RFC:
let (foo = 10,
bar = (foo + 32)):
foo * bar
I, personally, do not like this, though this is just a proposal and not the final syntax. But I think that the strength of Lisp in its parentheses is for one simple reason - Lisp syntax is based on data structures, not plain text. And the simpler the syntax for these data structures the better. Representing lists via some syntax like colons, commas, and so on makes it harder to associate this with a simple list of things. So whether we’re talking about macros, the reliability of the expression boundaries, and the generality of the syntax, this is all possible because of parentheses.
And, since we’re not programming on punch cards anymore, instead of changing the syntax, we can use helper tools to deal with this parenthesis problem.
Editor support
The most well-known editor for Lisp is Emacs. Mainly because it is kind of a Lisp machine by itself, that implements its own Lisp dialect, called Emacs Lisp. No wonder, Emacs has pretty good support for Lisp editing and a lot of packages that help with this task.
Though I will use Emacs to show ways to interact with Lisp code, most of these features are available in other editors as well. And the first thing I want to talk about is color.
Coloring and dimming
Some code editors have a so-called rainbow mode, to color parentheses in different colors, to make the structure more apparent.
This functionality is not unique to Lisps and can be used with any language that uses parentheses to declare scope, but I think it is most useful with Lisps, due to how many parentheses are usually stacked together on one line.
Here’s our let snippet with colored parentheses:
(let* ((foo 10)
(bar (+ foo 32)))
(* foo bar))
This is close to using different parentheses as here, except works in any dialect of Lisp and does not require matching parentheses manually.
After a certain period, this may not actually be needed, since many Lisp hackers indent their code with a set of well-established rules, so indentation represents structure. Because of that, it is possible to dim parentheses away since they are not really needed to read properly formatted code:
(let* ((foo 10)
(bar (+ foo 32)))
(* foo bar))
This is similar to the approach of ditching parentheses, but does not require re-implementing parsers, and rewriting all the code to use the new syntax. Although, it does require proper formatting.
Formatting
Another one is also about indentation and formatting. In Lisp, parentheses are usually stacked at the end of the expression, while in C-like languages, vertical alignment is preferred. We can reformat that Racket code, and use only curly braces, to make it look more traditional:
{
let* {
{
foo 10
}
{
bar {
+ foo 32
}
}
}
{
* foo bar
}
}
This may seem ridiculous, but this is still a valid Racket code. I would recommend against doing this, but this is up to you to decide if you really want these C-like indentations in your code for some reason.
Some other formatting rules are around as well, for example, here’s another one with C-like formatting, but less hideous:
(define f
(lambda (x)
(lambda (y)
(* (+ x y)
(- x y)
)
)
)
)
Or another one that suggests aligning parentheses on the separate line, but vertically aligning those with their opening scope:
(define f (lambda (x)
(lambda (y)
(* (+ x y)
(- x y)
) ) ) )
Which is an interesting approach, and makes it easy to see the structure, but makes it a bit harder to modify such code. The main downside is that this will not work if different parentheses are used, because we’ll need to reverse their order:
{define f (lambda (x)
[lambda (y)
(* (+ x y)
(- x y)
) ] ) }
This is valid but looks wrong because the parentheses are seemingly in a reverse order. This will not happen with a C-like approach though:
{define f
(lambda (x)
[lambda (y)
(* (+ x y)
(- x y)
)
]
)
}
This brings us to the point of making it easier not only to read but also to write Lisp code, with editing tools.
Structural editing
Paredit, Smartparens, and Lispy are three most popular (AFAIK) packages for Lisp editing in Emacs.
Their main on-the-surface difference is in that Lispy adheres to shorter commands, while Paredit sticks to Emacs-style keybindings2, and Smartparens has both its own set and Paredit-like set:
| Paredit command | Paredit binding | Lispy binding | Lispy command |
|---|---|---|---|
paredit-forward |
C-M-f | j | lispy-down |
paredit-backward |
C-M-b | k | lispy-up |
paredit-backward-up |
C-M-u | h | lispy-left |
paredit-forward-up |
C-M-n | l | lispy-right |
paredit-raise-sexp |
M-r | r | lispy-raise |
paredit-convolute-sexp |
M-? | C | lispy-convolute |
paredit-forward-slurp-sexp |
C-) | > | lispy-slurp |
paredit-forward-barf-sexp |
C-} | «/kbd> | lispy-barf |
paredit-backward-slurp-sexp |
C-( | > | lispy-slurp |
paredit-backward-barf-sexp |
C-{ | «/kbd> | lispy-barf |
These tools prove that Lisp code is actually its AST. And just like parentheses allow us to write macros, with tools like Paredit, we are able to manipulate AST in our editor mostly the same way.
Automatic parenthesis insertion
But the number of key bindings you need to know by heart with Paredit or Lispy may scare some programmers. I’m one of those, and I didn’t really want to learn Paredit. For people like us, there are modes that automatically insert matching closing parentheses when we insert opening one.
There are many of these in Emacs, here are a few:
smartparens- great package, that has a lot of commands and Paredit-style commands for editing and navigation,electric-pair-mode- builtin mode, that works fairly well for non-Lisp languages, but is still usable with Lisps,auto-pair- another good package for automatic insertion of pair symbols.
These packages are fewer friction alternatives for Paredit and Lispy, but are more general and will work for most languages. But what if we combine the idea of removing parentheses from Lisp and using indentation to represent the structure, without actually removing parentheses?
Parinfer
Created by Shaun Lebron, Parinfer was what brought me into Lisp. Since my first line of Lisp code, I was using Parinfer, and therefore it’s fair to say that I am
But even though, Parinfer is a great tool, that allows me to focus on editing code without thinking about trees all the time, as in structural editing. And still allows me to reason about trees with simple indentation editing.
Someone said that Parinfer turns Lisp into Python. Well, this is half true. Parinfer is more like this SRFI:49:
define (fac x)
if (<= x 0) 1
* x
fac (- x 1)
Here’s the same code, but with all parentheses in place:
(define (fac x)
(if (<= x 0) 1
(* x
fac (- x 1))))
If we dim all parentheses completely, we’ll have problems with inline expression boundaries, so this is not an option.
For example, if in Scheme accepts any amount of arguments, so here (human) interpreter would think that we compare x against 0 and 1:
define fac x
if <= x 0 1
* x
fac - x 1
Python has syntax that provides a way to express inline boundaries without parentheses:
def fac(x):
if x <= 0: return 1
else: return x * fac(x - 1)
So no, Parinfer won’t turn your Lisp code into Python but will allow thinking less about parentheses most of the time, because it uses indentation to infer those for you.
But what exactly Parinfer does? It’s a bit complicated to explain, but it infers closing parentheses based on indentation, by enforcing a line invariant. So, whenever you insert spaces, in smart mode Parinfer preserves the structure, while also moving parentheses around if needed. This section of Parinfer’s site explains it by using gears. And you can try Parinfer demo editor. Here’s a recording of me messing around:

From my point of view, this is the nicest way to write Lisp code*, because it is both transparent and highly predictable. It does not require learning complex commands, and you still have a lot of automation, while being in full control of your code and indentation style. The only thing Parinfer enforces is line invariant, which can be simplified down to these examples:
| Correct | Incorrect | Line invariant notes |
|---|---|---|
( |
( |
Indentation specifies that [] is inner part of () form<br>Structure doesn’t match indentation in incorrect example. |
() |
() |
Absence of indentation means that [] and () are separate forms<br>Indentation doesn’t match structure in incorrect example. |
Remembering this, you can understand what will happen when you insert or delete indentation, which makes it quite easy to make predictable edits without shortcuts.
Although Shaun Lebron has archived the Parinfer library repository, there’s an excellent Rust port of Parinfer, with support for Vim and Kakoune. There’s also great Emacs package that uses this library, which has fully fledged Smart mode and works great.
However, I’ve put an asterisk here for a reason:
From my point of view, this is the nicest way to write Lisp code*, because it is both transparent and highly predictable.
As transparent and predictable as it is, Parinfer has one huge downside. The code must be formatted properly. This is not a problem when you’re the only one working on the project, and you format your code properly. But when working on a real-world application with a team, where everyone has their own view on how code should be formatted, there will be a lot of commits that just fix the indentation. Because Lisp is a free-form language, which is another property we get for free by using parentheses.
Being a good programmer
The last thing, that we can probably address is the programmers themselves.
That is, we are also responsible for /too many parentheses/problems.
For example, I’ve seen some inexperienced Scheme programmers, who do not know about let*, and write this code:
(let ((var1 10))
(let ((var2 (* var1 10)))
(let ((var3 (+ (/ var2 3) var1)))
(* var3 var3))))
Which uses 26 parentheses. Instead of:
(let* ((var1 10)
(var2 (* var1 10))
(var3 (+ (/ var2 3) var1)))
(* var3 var3))
Which uses 18 parentheses.
Or not using cond instead of nested if forms:
;; good
(cond (= 1 2) "what?"
(not (= 2 2)) "WHAT?"
(= (- (+ 1 "1") 1) 10) "THIS IS NOT JAVASCRIPT!!!"
:else "all good")
;; Why?
(if (= 1 2)
"what?"
(if (not (= 2 2))
"WHAT?"
(if (= (- (+ 1 "1") 1) 10)
"THIS IS NOT JAVASCRIPT!!!"
"all good")))
Actually, cond and let* are just a macro, that transforms to nested if and let forms respectively, so why would you write this by hand?
Macros can save us a lot of parentheses.
Here’s an example from Clojure for the Brave and True book chapter 9:
(let [saying3 (promise)]
(future (deliver saying3 (wait 100 "Cheerio!")))
@(let [saying2 (promise)]
(future (deliver saying2 (wait 400 "Pip pip!")))
@(let [saying1 (promise)]
(future (deliver saying1 (wait 200 "'Ello, gov'na!")))
(println @saying1)
saying1)
(println @saying2)
saying2)
(println @saying3)
saying3)
By defining enquene macro we can transform this code into:
@(-> (enqueue saying (wait 200 "'Ello, gov'na!") (println @saying))
(enqueue saying (wait 400 "Pip pip!") (println @saying))
(enqueue saying (wait 100 "Cheerio!") (println @saying)))
Which is both more generic, less entangled, uses fewer parentheses, and in fact, produces the very same code in the end.
There are a lot of helpful macros in Lisps, which expand language and allow you to do the same. However, we need to remember that macros are complex beasts, and often reading macro is really hard, so it’s better to document its complex transformations. So as a rule of thumb it’s not often feasible to write one when a function will do. But being able to do this is still a huge deal, as we are able to shape the language into our application instead of just using it as a tool.
-
While I do not find jokes in this comic funny (except maybe C one), the Lisp part is pretty representative of how non-Lispers see Lisps in general, which is unfortunate. ↩︎